项目概览
做了什么
把上传、任务排队、进度反馈、结果播放下载收束到一个 Web 工作台。支持常见音频格式上传,前端默认提示 MP3 / WAV / M4A / AAC,单文件上限 5GB。
将英文播客自动处理为可播放、可下载、可追踪进度的中文播客成品,打通从上传到结果交付的端到端 AI 工作流。
起因是现有播客处理工具太碎:转写、翻译、合成、混音分散在多处。这个项目把链路收束成可跑通、可续跑、可演示的音频翻译 MVP。
项目概览
把上传、任务排队、进度反馈、结果播放下载收束到一个 Web 工作台。支持常见音频格式上传,前端默认提示 MP3 / WAV / M4A / AAC,单文件上限 5GB。
目标结果
线上 Demo 使用 Mock Pipeline;真实 AI 音频链路已在本地完成长音频端到端验证,并最终产出 MP3 音频文件。
约束条件
长音频处理耗时长、步骤多、外部服务依赖复杂,用户需要能看懂进度、知道是否完成,并在中断后继续。
Case Focus
把产品闭环、真实验证、任务恢复和职责边界放在一处看,减少重复信息。
Product Loop
登录、上传、任务创建、进度查看、播放下载与个人中心组成可演示路径。
Real Validation
真实链路已完成长音频端到端验证;线上 Demo 使用 Mock Pipeline 保持稳定体验。
Recovery
支持阶段级 checkpoint、分段产物复用;provider 异常暂停,修复后从当前阶段继续。
Role
个人项目,负责产品设计、前后端实现、异步任务编排、AI Pipeline 集成、Docker 部署与真实链路验证。
Stack
按实现层和工具层拆开,方便快速判断协作范围。
前端体验层
Next.js 15 / React 19 / TypeScript / Zustand后端 API 层
FastAPI / SQLAlchemy异步任务层
Celery / Redis数据与产物层
PostgreSQL / MinIO / S3 / AlembicAI 音频流水线层
Demucs / pyannote.audio / faster-whisper / DeepSeek / ElevenLabs IVC / FFmpeg工具层:DashScope / CosyVoice fallback / FFmpeg / pydub / Pytest / Docker Compose / Nginx
Workflow
真实链路按 7 个阶段推进,页面只展示用户需要理解的处理进度与交付结果。
整理原始音频结构,为后续识别、生成和重组提供稳定输入。
识别不同说话人的时间分布,保留播客对话的基本结构。
将英文语音转换为可处理文本,并按片段持续推进任务状态。
在保留语境和表达节奏的基础上生成中文内容。
按说话人和片段生成中文音频,异常时保留已完成产物。
让生成音频贴合原始节奏,减少长短句带来的听感割裂。
合并语音与背景音,生成可播放、可下载的最终音频。
Proof
用真实界面截图和可播放产物呈现项目可信度。
screenshot
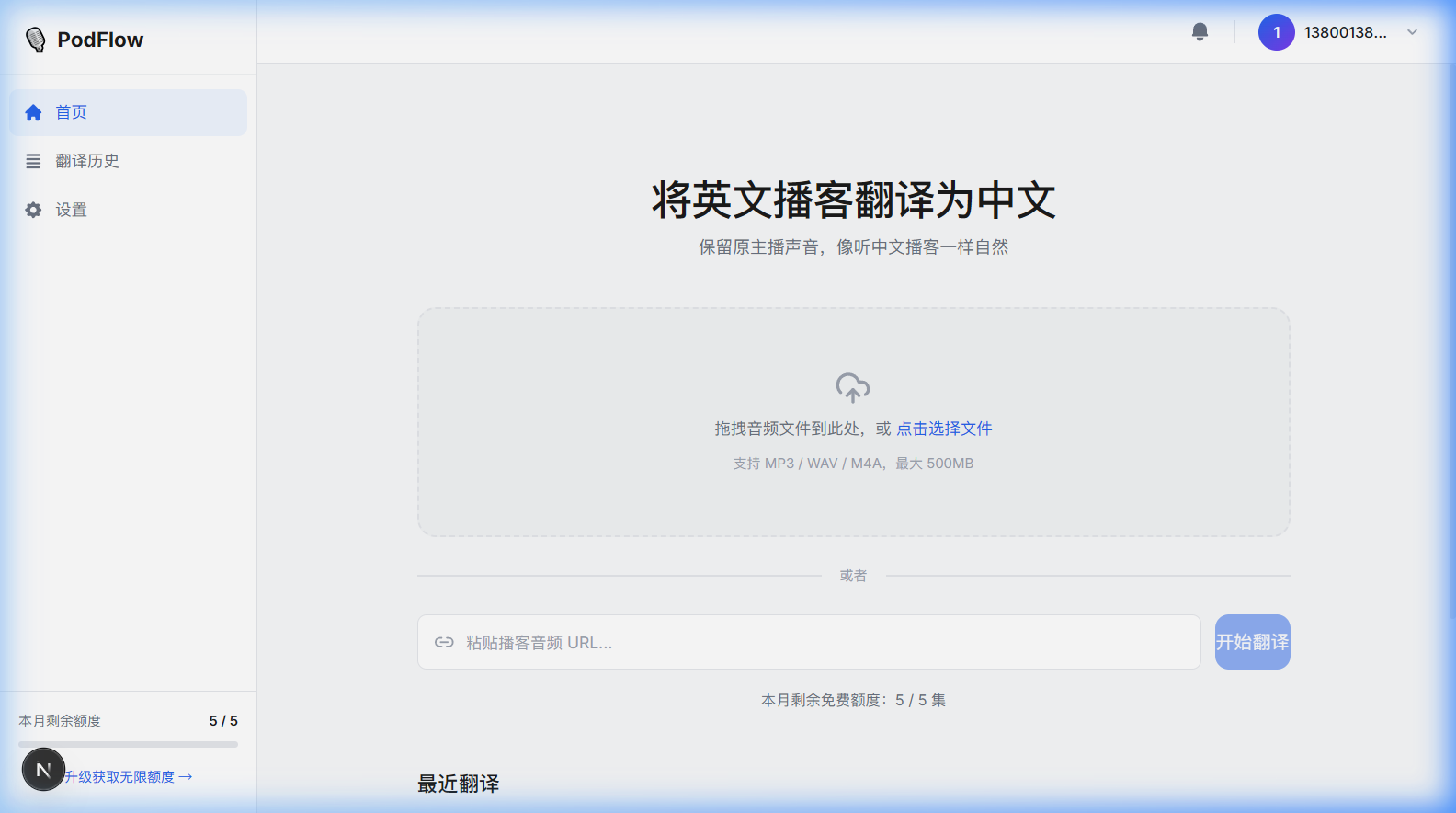
上传入口展示音频文件拖拽、URL 输入、额度提示和最近任务,是公开 Demo 的主要起点。
支持常见音频格式上传,前端默认提示 MP3 / WAV / M4A / AAC,单文件上限 5GB。
screenshot
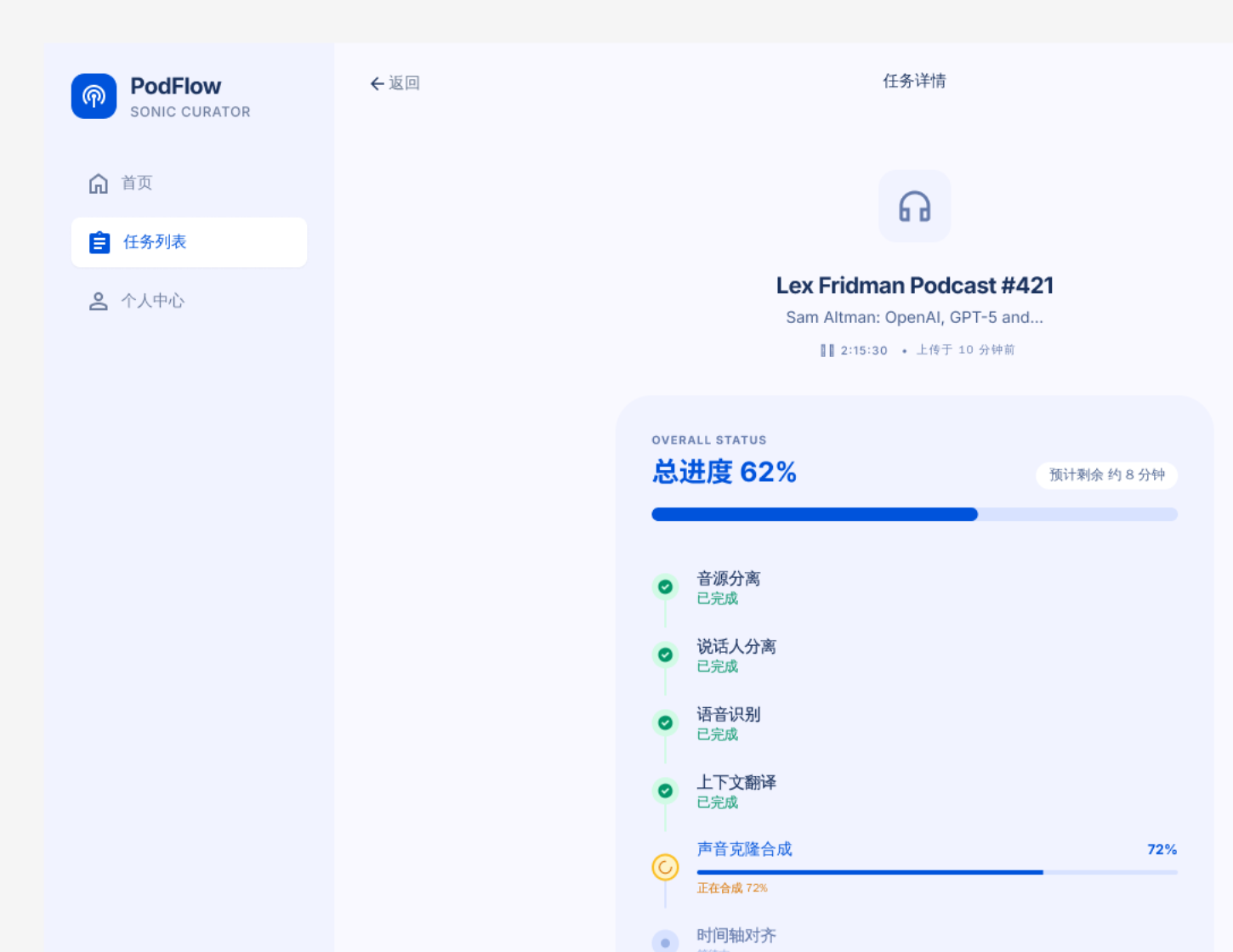
任务详情页展示总进度、当前阶段、阶段完成状态、预计剩余时间和暂停处理入口。
证明点:长任务不再是黑盒等待;阶段状态可追踪,也能为断点续跑提供用户可理解的反馈。
output
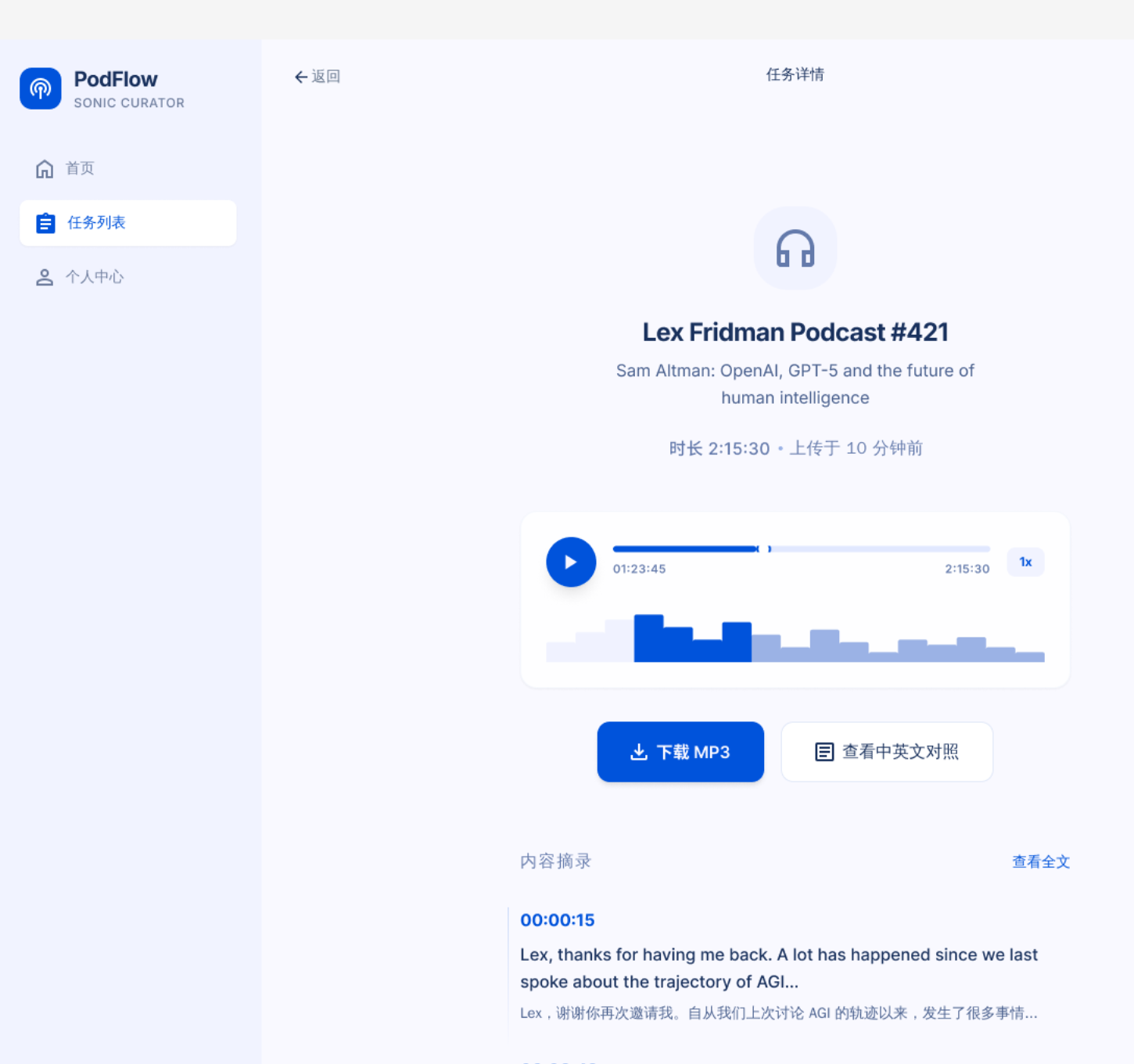
任务完成后提供最终音频播放、下载 MP3 和中英文对照查看,覆盖结果消费闭环。
本地真实链路验证产物可试听:final_podcast.mp3。
试听 final_podcast.mp3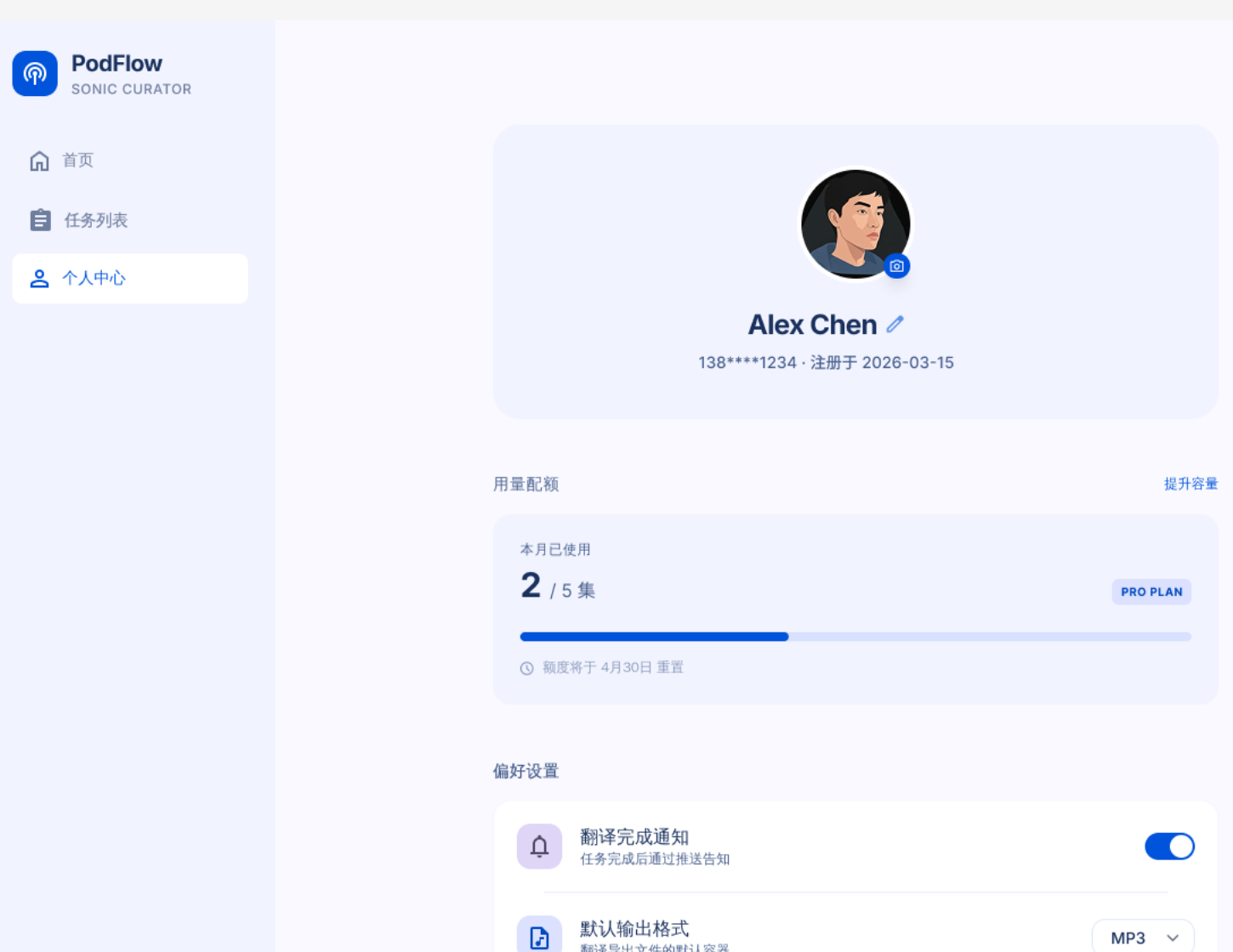
screenshot
个人中心支持用户级 provider 配置,覆盖 DeepSeek、OpenAI、Hugging Face、ElevenLabs 和 DashScope。
provider 凭证缺失、余额不足或额度耗尽时,任务会 paused 而不是 failed,修复后可从当前阶段继续。
想看流程跑起来?